Closing down for a day
crawling and indexing search results UXNote: This post is specific to Google's organic web-search. For Google's other services, please check with the appropriate help center (e.g., for Google Shopping) or help forum.
Even in today's "always-on" world, sometimes businesses want to take a break. There are times when even their online presence needs to be paused. This blog post covers some of the available options so that a site's search presence isn't affected.

Option: Block cart functionality
If a site only needs to block users from buying things, the simplest approach is to disable that specific functionality. In most cases, shopping cart pages can either be blocked from crawling through the robots.txt file, or blocked from indexing with a robots meta tag. Since search engines either won't see or index that content, you can communicate this to users in an appropriate way. For example, you may disable the link to the cart, add a relevant message, or display an informational page instead of the cart.
Option: Always show interstitial or pop-up
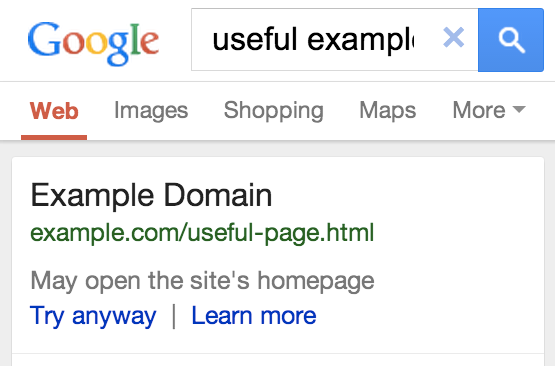
If you need to block the whole site from users, be it with a "temporarily unavailable" message, informational page, or popup, the server should return a 503 HTTP result code ("Service Unavailable"). The 503 result code makes sure that Google doesn't index the temporary content that's shown to users. Without the 503 result code, the interstitial would be indexed as your website's content.
Googlebot will retry pages that return 503 for up to about a week, before treating it as a permanent error that can result in those pages being dropped from the search results. You can also include a "Retry after" header to indicate how long the site will be unavailable. Blocking a site for longer than a week can have negative effects on the site's search results regardless of the method that you use.
Option: Switch whole website off
Turning the server off completely is another option. You might also do this if you're physically moving your server to a different data center. For this, have a temporary server available to serve a 503 HTTP result code for all URLs (with an appropriate informational page for users), and switch your DNS to point to that server during that time.
- Set your DNS TTL to a low time (such as 5 minutes) a few days in advance.
- Change the DNS to the temporary server's IP address.
- Take your main server offline once all requests go to the temporary server.
- … your server is now offline ...
- When ready, bring your main server online again.
- Switch DNS back to the main server's IP address.
- Change the DNS TTL back to normal.
We hope these options cover the common situations where you'd need to disable your website temporarily. If you have any questions, feel free to drop by our webmaster help forums!
PS If your business is active locally, make sure to reflect these closures in the opening hours for your local listings too!